
3 Biological Macromolecules
Learning Objectives
- Identify types of macromolecules and their monomers based on molecular structures
- Predict macromolecular shapes and interactions based on molecular structure
- Explain the relationship between a molecule’s structure and its function in the cell
- Course-level objective: Accurately use course vocabulary in models, explanations, and scientific arguments
A key idea for biology that we’ll be exploring throughout this book is how the structure of molecules relates to the function of those molecules. By extension, this means that by changing the structure, we can change the function. For instance, look around your room and think of everyday objects that you see have a particular structure that supports their function. For example, on my desk, I have several keys like those shown in Figure 3.1, and I know that only one of these keys fits into and will turn a particular lock. Because of the structure of the key and the structure of the lock, the pieces must fit together for the unlocking function. What similar examples of structure supporting a function can you observe around you?

Another relevant feature of living things is that they show complexity and organization. A goal of this unit is to understand what cells are made of, how those components are organized, and how the structure of a molecule helps support its function. Every function that cells carry out is dependent upon the structures and specific molecules that those cells contain. If we were to take apart cells and examine all their components, we’d first find that cells are mostly water—roughly 70%! The largest category of molecules, just under 30%, would be macromolecules, or large organic molecules made by cells. Only a small fraction of the material in cells are ions and small molecules, including the monomers that are used to build macromolecules.
Chapter Outline
Section 3.1 Overview of Macromolecules and Their Synthesis
Section 3.1 Overview of Macromolecules and Their Synthesis
Within the category of macromolecules, we find four different types of macromolecules: proteins, nucleic acids, carbohydrates, and lipids. Every cell has the same types of macromolecules in roughly the same proportions. Macromolecules are created via chemical reactions that join specific building blocks, or monomers, using covalent bonds.
Because these reactions also produce water, these are called dehydration synthesis reactions. Figure 3.2 shows one example of this reaction. Each monomer has atoms in specific functional groups that will react with each other. When this reaction occurs, a new covalent bond forms between the monomers and along with releasing water. The molecule that contains the two joined monomers is called a dimer. If we were to repeat this synthesis reaction and join a new monomer to the dimer, water would again be a product of that reaction, and we would now have a trimer. No matter what synthesis reaction that we are talking about or what macromolecule we’re making, it’s the same type of reaction each time, always forming water when the new covalent bond is made.
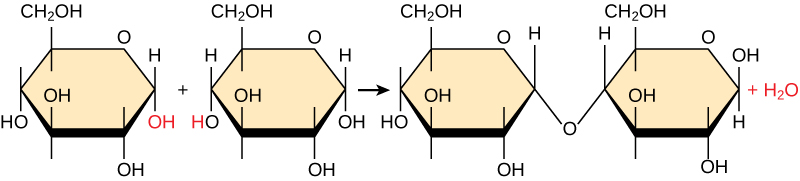
Conversely, to break down macromolecules, a hydrolysis reaction, which splits water to provide the atoms to break off monomers from the chain, is used (Figure 3.3).
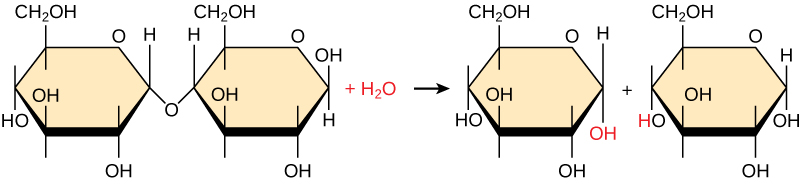
Subsequent chapters will provide more details on how some specific macromolecules are made. For each section, focus on identifying key characteristics of each type of macromolecule, the characteristics of the building blocks (monomers) for each macromolecule, the functional groups involved in making the covalent bond and the specific name for that covalent bond, the general functions of each macromolecule, and (where possible) how the structure of the macromolecule supports its function.
Section 3.2 Carbohydrates
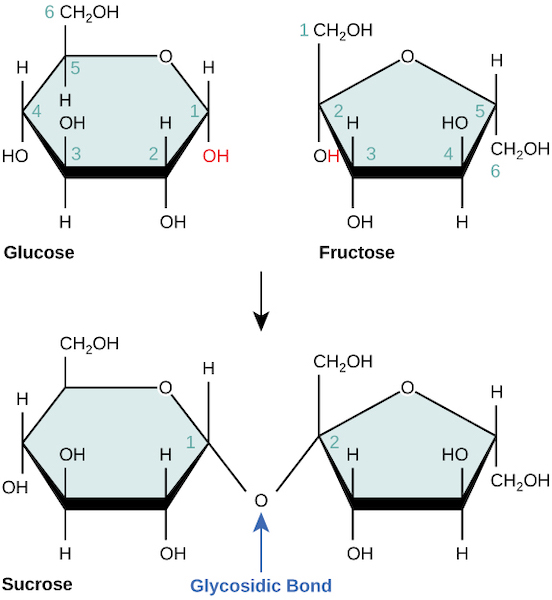
Carbohydrates are sugars, and contain carbon, hydrogen and oxygen in roughly a 1:2:1 ratio. You are likely familiar with several specific monomers, dimers, and polymers of this class of molecules. For example, glucose is a simple sugar, or monosaccharide, sucrose (table sugar) is a disaccharide (dimer) containing the simple sugars glucose and fructose, and starch (found in bread and potatoes) is a polysaccharide (polymer) of glucose. No matter the format, you can recognize and remember the general structure of carbohydrates by just thinking about the name: carbohydrate = carbon + H2O. Fig 3.4 shows the formation of the covalent bond between sugar monomers, appropriately named a glycosidic bond (‘glyco-‘ means sugar).
Several important polysaccharides are built by linking hundreds or thousands of glucose monomers, such as starch and cellulose (made by plant cells) and glycogen (made by animal cells). All these polysaccharides are made from the same building block, and joined by glycosidic bonds, but the way in which these monomers are joined together varies. Compare the way in which glucose monomers are arranged in amylose or amylopectin, which are staight or branched forms of starch, respectively (Figure 3.5), versus in cellulose fibers (Figure 3.6).

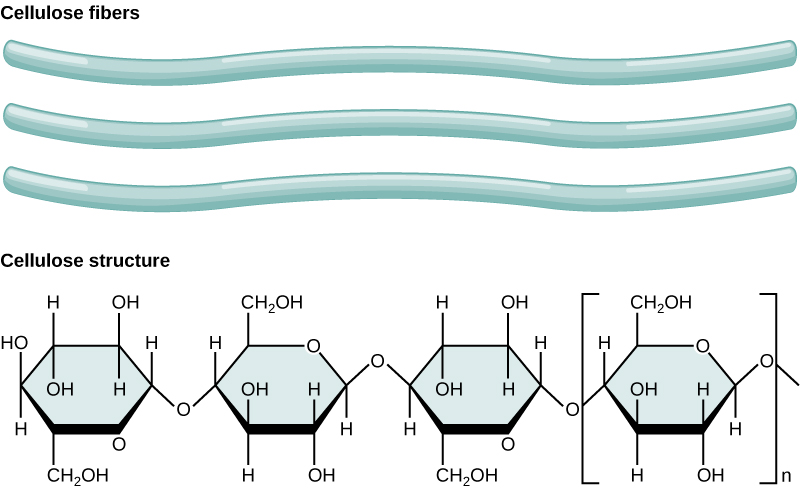
The difference in the specific type of glycosidic bond affects the structure of the molecule, which in turn affects the function: the branched structure of amylopectin keeps the structure more open, whereas the fibers of cellulose can be densely packed to maximize intermolecular interactions, allowing it to be very rigid and form the support structure for the cell walls of plants. Additionally, the linkages between glucose molecules in cellulose are chemically very stable, which makes this molecule very hard for most organisms, including us, to break down. In fact, there are very few organisms on planet Earth that can digest cellulose, which makes it the most abundant macromolecule on the planet. The bonds within starch, however, are easily broken when needed, aided by the branched and open structure that allows easier access for enzymes that facilitate the chemical reaction. Thus, starch is an energy storage molecule, made when glucose is abundant and easily broken down when glucose is needed. Animal cells make glycogen, which is like starch in that it has a highly branched structure, is formed from glucose monomers, and is a way to store glucose energy for later use. We will discuss in a later chapter how cells use extract the energy from glucose to produce ATP from ADP and Pi. The breakdown of ATP into ADP and Pi then provides energy for many other reactions in the cell that require it.
Section 3.3 Lipids
Lipids are a special class of macromolecules in that they are not characterized by a specific monomer building block, but rather by their chemical property: lipids are primarily hydrophobic molecules, containing mainly nonpolar covalent bonds that do not interact well with water or other polar solvents.
One type of lipid you are undoubtedly familiar with is triacylglycerol, otherwise known as fat or oil. If you’ve ever eaten oil or butter, you have consumed triacylglycerols (also known as triglycerides). The function of this macromolecule is for energy storage, and we will discuss in a later chapter how cells extract energy from fats. Structurally, a triacylglycerol is a macromolecule formed from glycerol and three fatty acids, as shown in Figure 3.6.

The carboxyl group on each fatty acid reacts with a hydroxyl group on glycerol, forming ester linkages and three molecules of water after synthesis. Despite the presence of oxygen bound to carbon in this molecule, the nature of ester bonds reduces their polarity and this entire triacylglycerol molecule is hydrophobic. Notice how the fatty acids can differ within the molecule in terms of their length. Also, these fatty acids can either have the maximal number of hydrogens bound to carbon (saturated, Figure 3.7, top) or have one or more double bonds between carbons in the chain, which reduces the number of hydrogens (unsaturated, Figure 3.7, bottom).
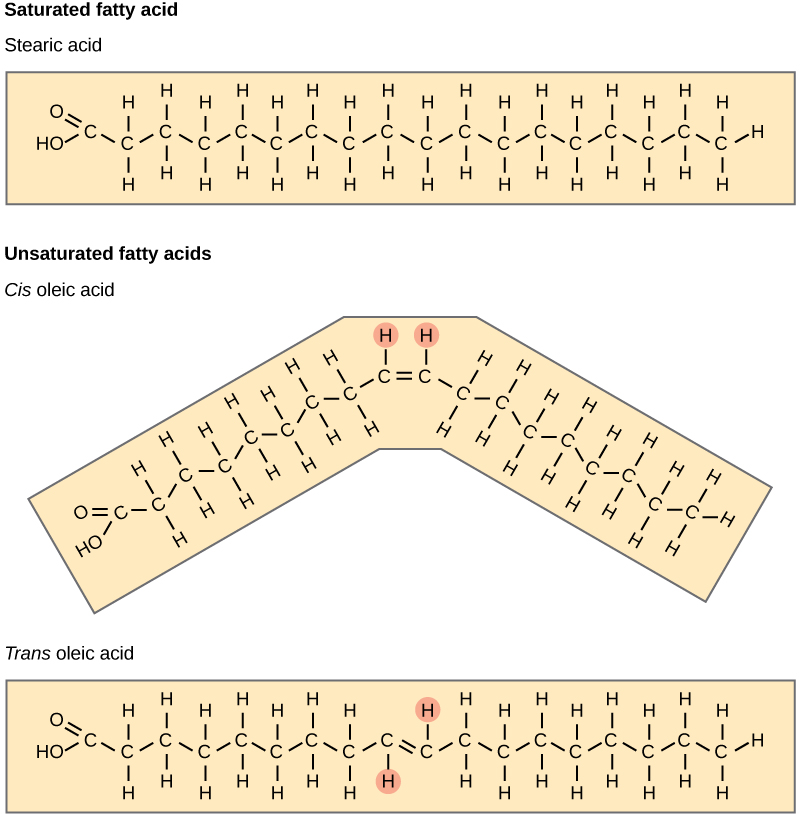
Typically, fatty acids that are unsaturated (oils) are liquid at room temperature, whereas saturated fatty acids are solid (think of butter). We can understand this by considering the structure of the fatty acids and applying our knowledge of intermolecular forces from Chapter 2. Because fatty acids are hydrophobic, the only attractive forces that occur between these are LDFs. Recall that LDFs are extremely weak, so molecules must be very close together for those LDFs to have an effect. A saturated fatty acid, with only single bonds in the carbon chain, is very flexible and can be pushed into a straight shape that allows for close packing with other saturated fatty acids. This creates opportunities for many LDFs, each acting like a little piece of Velcro, along the length of the fatty acid tails. These interactions are individually weak, but in large numbers can slow down molecular movements and cause the overall solution to be in a solid phase.
As shown in Figure 3.7, a double bond in the carbon chain can be either in the ‘cis’ or ‘trans’ configuration, but only the ‘cis’ version is typically found in nature. In contrast to the flexible single covalent bonds, a double bond imposes a bend in the structure that restricts movement. As a result, unsaturated fatty acids are less flexible and cannot pack closely together, resulting in fewer LDFs between fatty acid molecules. A solution of ‘cis’ unsaturated fatty acids, therefore, is a liquid at room temperature. With that in mind, consider again the ‘trans’ fatty acid in Figure 3.7. Would you predict a solution of ‘trans’ unsaturated fatty acids to be solid or liquid at room temperature, and why?
Figure 3.8 shows two types of lipids that are typically found in cellular membranes, cholesterol (3.8a) and phospholipids (3.8b).
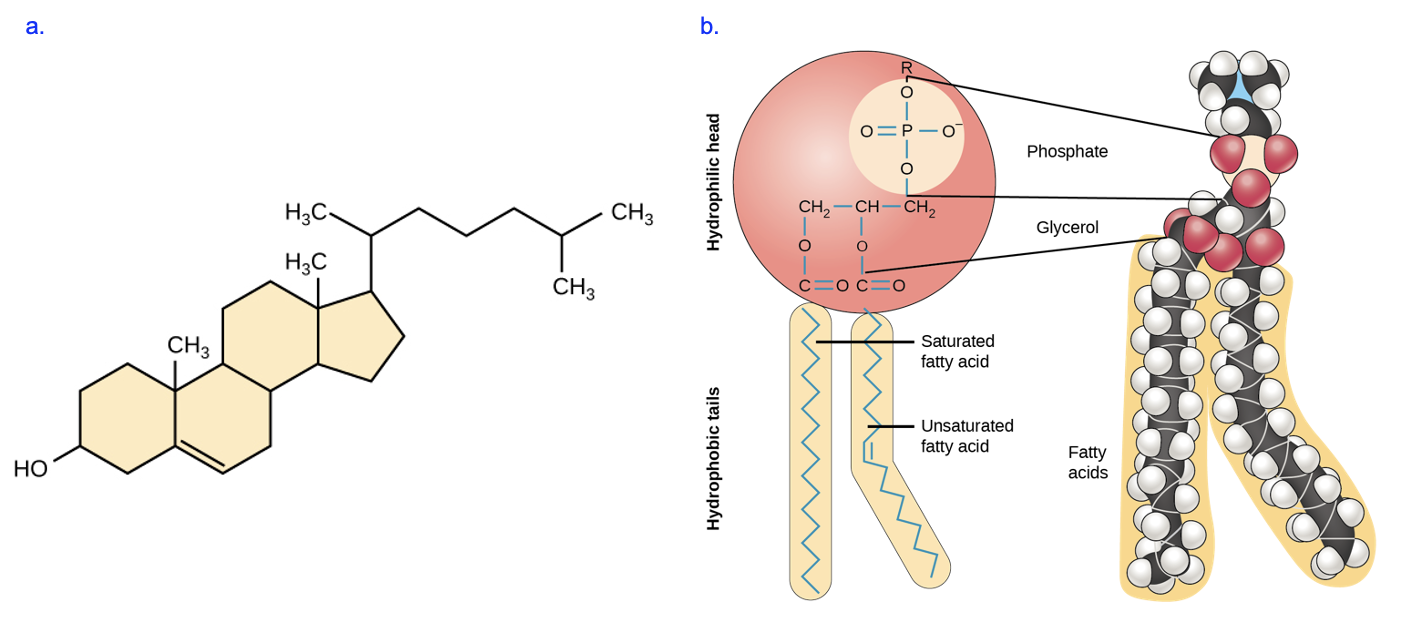
These lipids are very different in structure, but one feature they have in common is the presence of distinct hydrophobic regions. Cholesterol is nearly entirely composed of hydrocarbons, and phospholipids have two fatty acid tails similar to those observed in the triacylglycerols discussed above. However, these lipids are distinct from the triacylglycerol molecule in Figure 3.7 in that they also have hydrophilic regions. Cholesterol has one hydroxyl group that is polar (bottom left of Figure 3.8a, while a phospholipid has a phosphate group that is charged (top of Figure 3.8b). The R group indicated in the model in Figure 3.8b, above the phosphate, is typically polar or charged as well.
This unique combination of hydrophobic and hydrophilic regions, also referred to as amphipathic, allows these lipids to form membranes in cells. As we will see in later chapters, membranes function as barriers to help keep the contents of the cell contained and separated from the external environment, and control the flow of molecules inside and outside of the cell. Under cellular conditions, phospholipids arrange into a bilayer membrane, in which the hydrophobic fatty acid tails cluster together, away from water, while the polar (hydrophilic) head groups are oriented to the aqueous exterior or interior fluids (Figure 3.9). Cholesterol is not shown in this model, but based on its structure, how do you think it would be inserted into the bilayer?
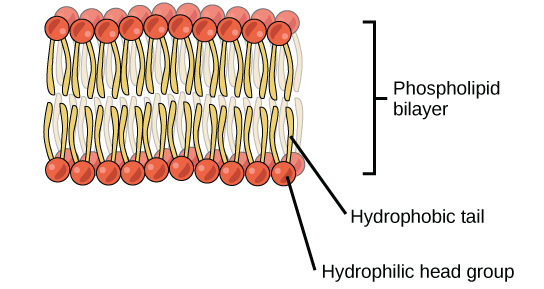
As we saw with triacylglycerols, the fatty acid tails of phospholipids can be saturated or unsaturated, causing cellular membranes to be less or more fluid, respectively, which in turn impacts the barrier function. We will discuss the importance of membrane fluidity, and how and why this is regulated in cells, in a later chapter.
Section 3.4 Proteins
Proteins are the most abundant macromolecules in cells, in part because they carry out many essential functions of cells, which is in turn due to the fact that proteins are very diverse in structure. Proteins facilitate chemical reactions, provide structure, transport molecules, and much more. As described by the central dogma, proteins are synthesized by cells using information from mRNA, which was previously synthesized using information from DNA. The structure of proteins gives insights into their functions. For example, porin is a protein found in certain cell membranes, and it allows substances to cross those membranes. In the structure of porin, you see several large pores, which are holes through which substances that are small enough can move (Figure 3.10a). Some proteins, such as collagen, give structure to the cell. We can see the structure of collagen is a long rod formed of several segments that are twisted together, and these extensive intermolecular interactions give the molecule substantial strength (Figure 3.10b).
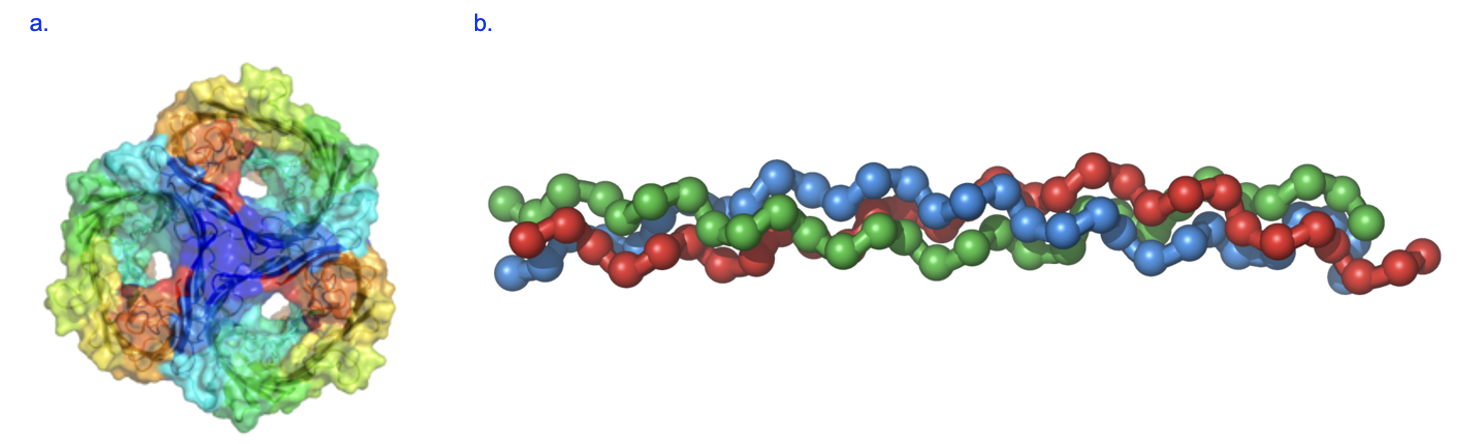
No matter which protein we examine, we find that proteins are chains of amino acid monomers. The structure of the amino acid helps explain how it earned its name (Figure 3.11).
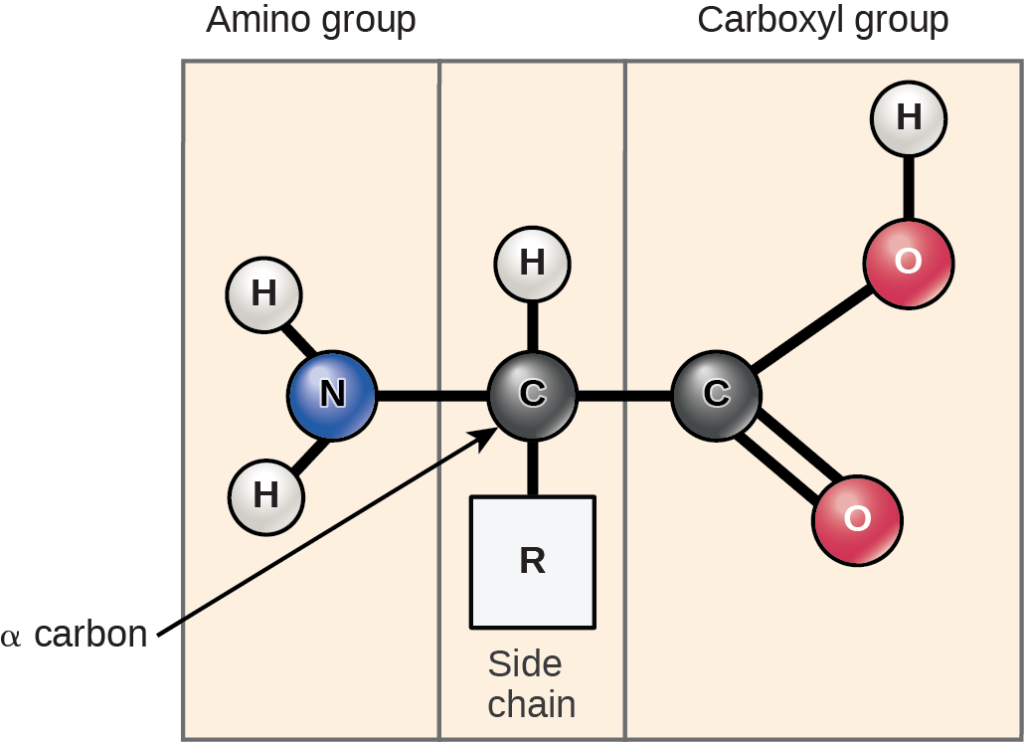
An amino acid contains an amino group (H2N or more typically H3N+-, that’s where the amino part of the name comes from!) and a carboxyl group (COOH or more typically COO–, that’s the acid part, because this group has donated a proton to the surrounding environment). Both groups are attached to the central or alpha carbon, along with an R group or side chain. Figure 3.12 shows the 20 amino acid monomers commonly found in proteins.

Note how only the side chain varies from one type of monomer to another. Thus, we must use the characteristics of the R groups to categorize amino acids into groups such as nonpolar, polar uncharged, and charged. We will discuss the implications of these different groupings in a later chapter on protein structure.
When multiple amino acids are attached together, they form a polypeptide. This name arises because those individual amino acid monomers are joined by a specific covalent bond called a peptide bond. Let’s look in a little more detail at how this peptide bond forms. Figure 3.13 shows two amino acid monomers. Note the position of the carboxyl group in the first amino acid that is adjacent to the amino group of the second amino acid. Remember, when this dehydration synthesis reaction occurs, water is removed, and we can see the oxygen and two hydrogens from the functional groups on each monomer that will form the water molecule. The covalent peptide bond forms between the carboxyl carbon and the amino nitrogen to join these amino acids.
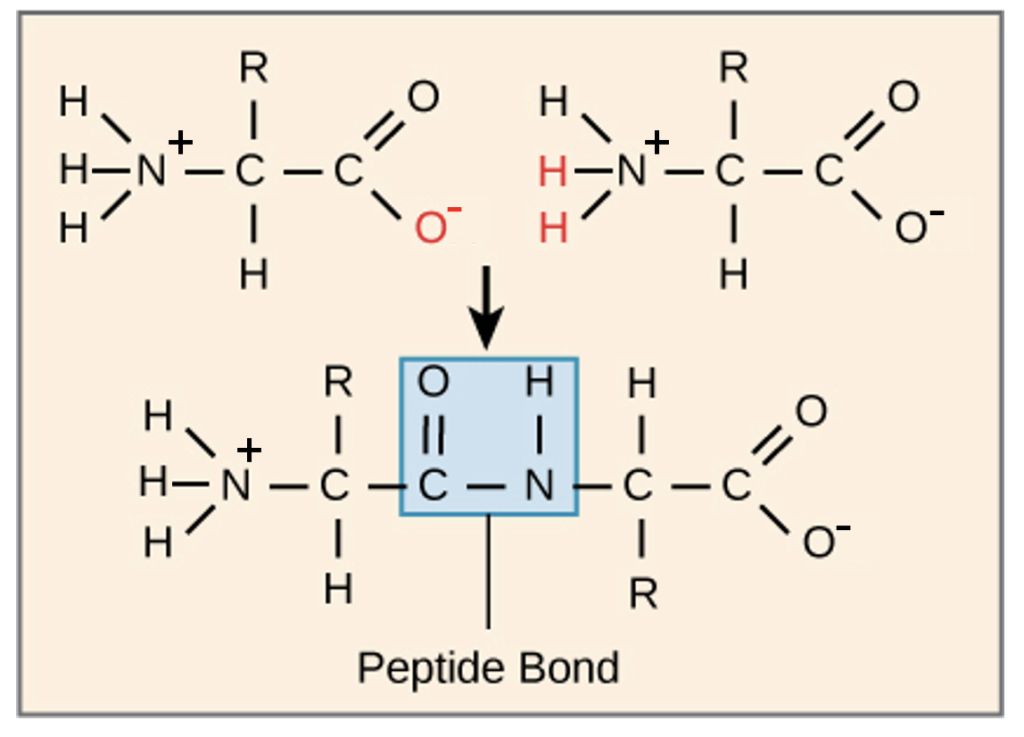
The functional groups that were joined to create the dimer are modified (compare with the free monomers), while the first amino acid still has a free amino group and the second amino acid has a free carboxyl group, same as in the original monomer. Additional amino acids will be added to the chain in a similar reaction, building off the free carboxyl group. Every polypeptide will thus contain a free amino and a free carboxyl end, which are called the amino (N) terminus and carboxy (C) terminus, respectively. Importantly, as shown in Figure 3.13, the R groups of the amino acids are not involved in the formation of the peptide bond, and these R groups will vary throughout the chain. In contrast, the atoms forming the peptide bond are identical down the length of the polypeptide, and constitute the backbone of the chain.
Section 3.5 Nucleic acids
Nucleic acids, which include deoxyribonucleic acid (DNA) and ribonucleic acid (RNA), are my favorite class of macromolecule, as these molecules are involved in storing and transmitting genetic information. As we know from the central dogma, the information in DNA is used to make RNA, and the information in RNA is used to make a protein. Proteins, remember, carry out the important tasks in a cell and give the cell its characteristics. The properties of proteins come from the information in DNA and RNA that encodes them. Therefore, if we want to change the proteins to have them do different things, we have to start with the DNA. In the next chapter, we’ll talk about how that information transfer occurs in the gene expression process.
For now, let’s focus on the building blocks and overall structure of DNA and RNA. DNA and RNA are both nucleic acid macromolecules. The monomer building blocks that are used to build those macromolecules are called nucleotides, and there’s RNA and DNA versions of these nucleotides. First, let’s focus on the similarities – all nucleotides have three components: a phosphate group, a five-carbon sugar (the ring-shaped structure), and a nitrogenous (nitrogen-containing) base (Figure 3.14). Note that certain carbons in the sugar molecule are numbered. The first carbon, or the one prime (1’) carbon, is the carbon of the sugar ring to which the nitrogenous base is attached. After that, carbons are numbered in order moving around the ring away from the oxygen until the final, 5’ carbon is reached. Below the labeled nucleotide, note the two different sugar structures, which differ only in the groups attached to the 2’ carbon. RNA nucleotides have a hydroxyl (OH) group attached to the 2’ carbon, while DNA nucleotides have a H only. This is where the “deoxy” part of DNA comes from—there is one less oxygen in the sugar of a DNA nucleotide. There are also differences in the bases found in DNA versus RNA, shown to the right of the labeled nucleotide. While DNA nucleotides have cytosine, thymine, adenine, or guanine bases (we can abbreviate as C, T, A, or G, respectively), the bases in RNA nucleotides are cytosine, uracil, adenine, or guanine (C, U, A, or G). Thymine is not found in RNA sequences, and uracil is not found in DNA sequences.
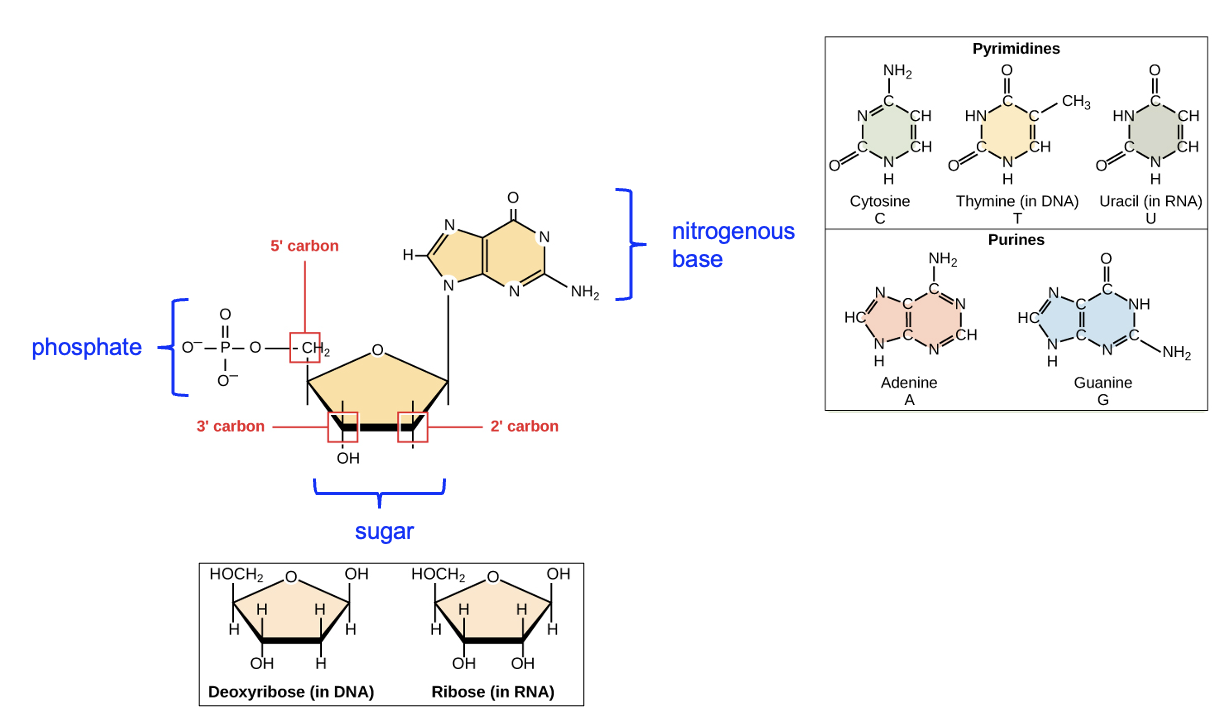
Now let’s think about how these nucleotides would be joined together to make a nucleic acid macromolecule. Look again at the sugar in Figure 3.14. Both DNA and RNA have a hydroxyl group attached to the three prime (3’) carbon, and a phosphate group attached to the 5’ carbon. These names, 5’ and 3’, are commonly used to describe parts of the nucleotide and the macromolecule polymer formed from those nucleotides. Figure 3.15 shows a DNA double helix consisting of two DNA strands, which is how DNA is typically found in cells. Note that within a strand, the sugar of one nucleotide is connected to the phosphate of the next nucleotide, forming a phosphodiester linkage. Each strand in the image has three linkages, though only one is labeled. Compare the macromolecule with the monomers in Figure 3.14—which two functional groups reacted to form the linkage?
Looking at the macromolecule strands once again, notice that each strand has a free phosphate group at one end and a free hydroxyl group at the other end. These are the 5’ and 3’ ends of the nucleic acid, and the chemical differences between these ends gives each nucleic acid directionality, and we will see that strands are only read in a particular direction that is important for correctly reading the information. These names, 5′ and 3′, are commonly used to describe both individual nucleotides and nucleic acid polymers, and you will need to identify these on strands to help explain gene expression (Chapter 4) and DNA replication (Chapter 20).
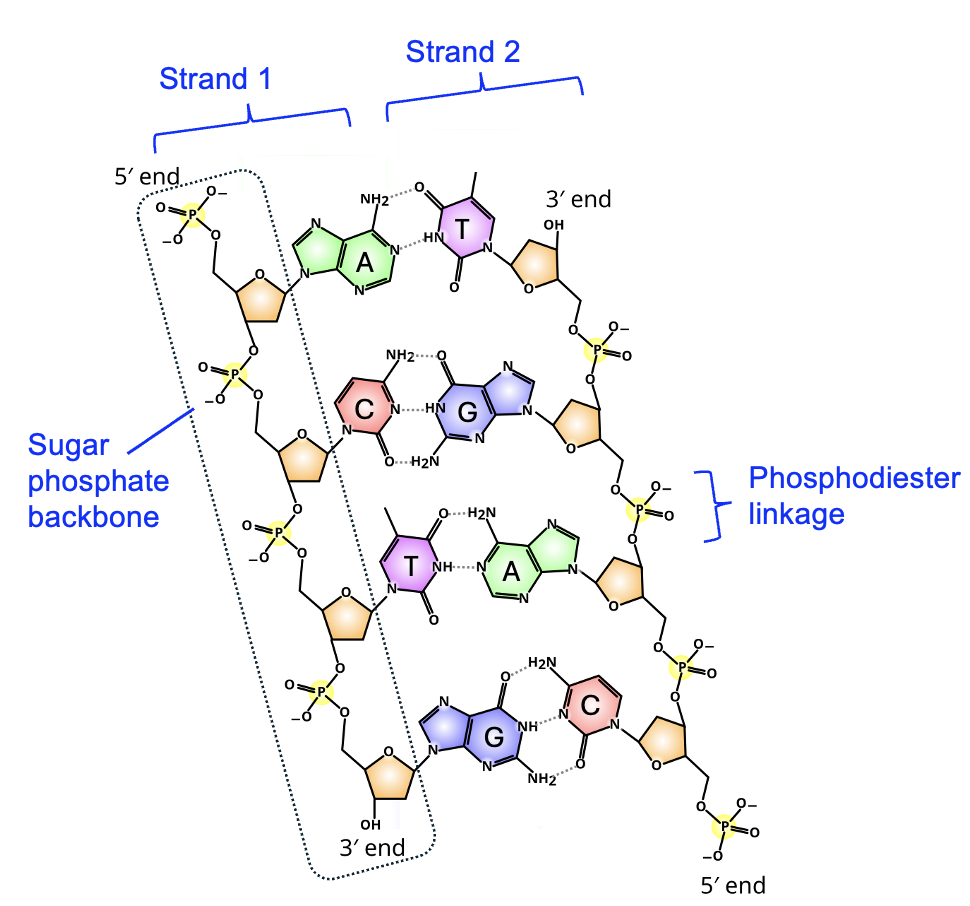
Another important feature of the double helix is that the phosphates and sugars are connected in the strand, and form the backbone of the DNA strand. The bases themselves are in the interior of the helix, each base interacting with one specific base on the other strand of DNA. Look closely at the functional groups involved in this interaction, considering what you learned from Chapter 2. These functional groups are polar and interact with each other using hydrogen bonding. Moreover, the partial charges on the functional groups are such that only certain pairs of bases are compatible. A only pairs with T, and G only pairs with C. The interaction between bases of nucleic acids is commonly known as base pairing.
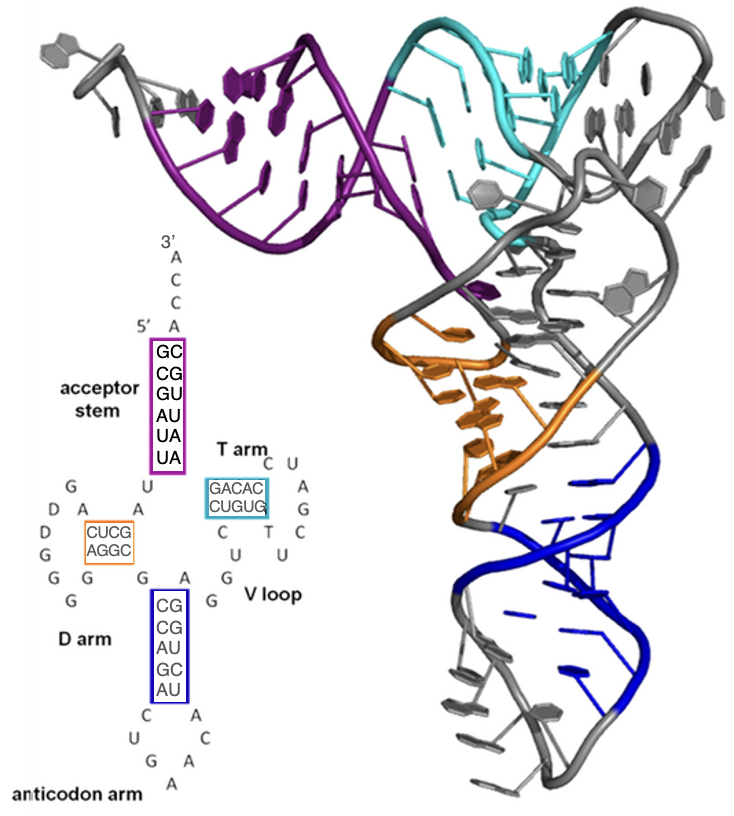
In contrast to DNA, RNA molecules in the cell are almost always single-stranded. However, as we will see in Chapter 4, RNA nucleotides base pair with DNA in the process of synthesizing the RNA. Once created, some RNA molecules (referred to as mRNA) are then used to make a protein in the process of translation. However, many more types of RNA are never translated and carry out important functions within the cell as RNA molecules (referred to as functional RNAs). Single-stranded RNA molecules often fold back on themselves using base pairing that stabilizes that folding. The base pairing rules are similar but not identical to those described above. Importantly, the ability of RNA strands to base pair within the RNA strand allows RNA molecules to have complex three-dimensional structures. Some RNA molecules can even facilitate chemical reactions much like enzymes (which are a type of protein)! Figure 3.16 shows a tRNA, which is a single-stranded RNA that plays a key role in the process of translation, or using a strand of RNA to make a protein (to be discussed further in Chapter 5). As with DNA, the hydrogen bonds between the nitrogenous bases of the nucleotides stabilize the three-dimensional structure that is essential for its function.
large organic molecules made by cells
a building block for polymers
a chemical reaction that creates a covalent bond between monomers and produces water
sugar molecules that contain carbon, oxygen and hydrogen in roughly 1:2:1 ratios
monomer of carbohydrates, also known as a simple sugar
a covalent bond formed between sugar monomers in the synthesis of a disaccharide or polysaccharide molecule.
class of macromolecules that are primarily hydrophobic
having distinct hydrophobic and hydrophilic regions
macromolecule made up of amino acid monomers that carries out most functions of the cell
the building block of proteins, containing an amino group, a central carbon, an R group, and a carboxyl group
a sequence of amino acids joined by peptide bonds
a type of covalent bond that joins amino acid monomers into a polypeptide chain
macromolecule made up of nucleotides that stores and transmits genetic information
the monomer building block of a nucleic acid, consisting of a phosphate, 5-carbon sugar, and a nitrogenous base
a series of covalent bonds that joins nucleotides in a nucleic acid strand
