
5 Gene Expression 2: Using RNA to Make a Protein
Learning Objectives
- Predict the sequence of an mRNA produced by transcription from a gene diagram and sequence
- Predict the sequence of a protein produced by translation from a gene diagram and sequence
- Use a model to describe the process of translation
- Use a model to explain the overall process of how a cell uses genetic information (DNA) to produce proteins
In Chapter 4, we learned the first steps to gene expression, using the information in DNA to make an RNA by the process of transcription (Figure 5.1). Now, we will continue the story to see how the information in mRNA is decoded to produce a protein. Ultimately, many cellular phenotypes are linked to the actions of proteins produced by gene expression, although the non-translated functional RNAs are also important for cellular function. As we shall see, some of these functional RNAs are themselves critical for the translation process!
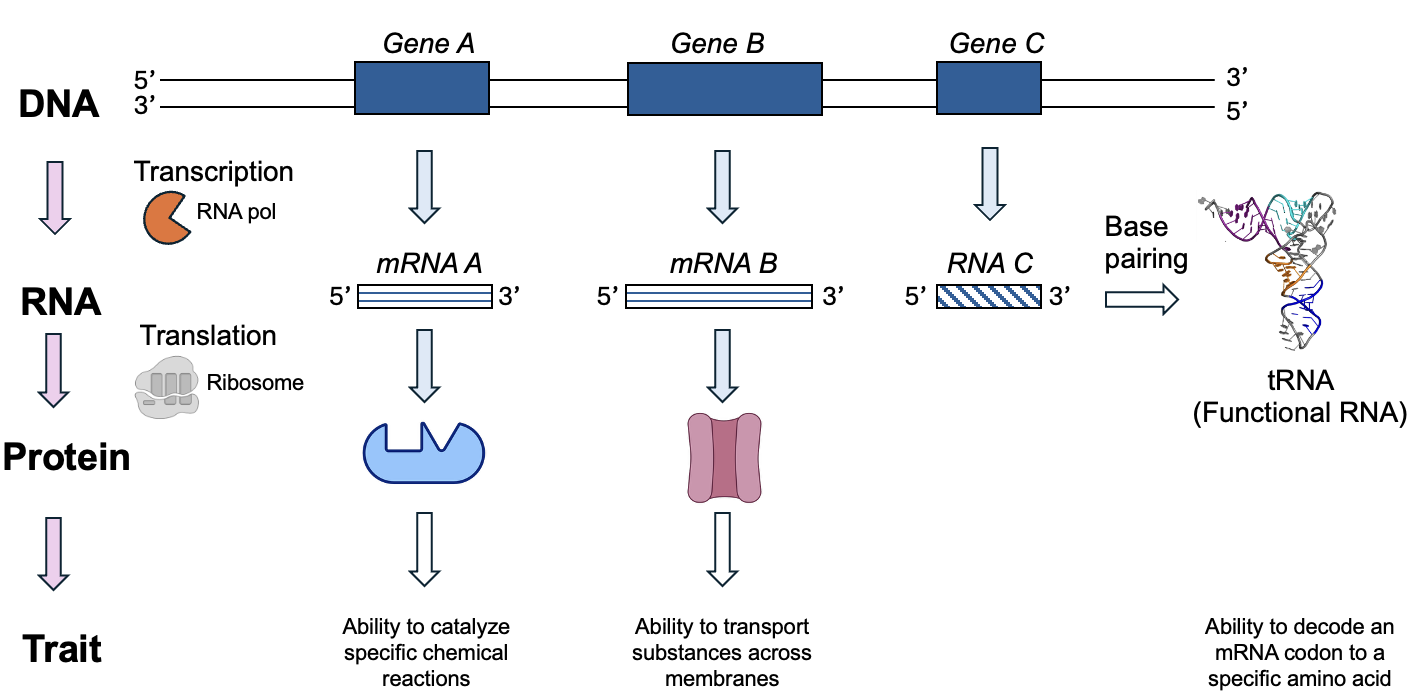
Chapter Outline
Section 5.2 Molecules of Translation
Section 5.3 Process of Translation
Section 5.4 Cellular Location of Translation
Section 5.1 The Genetic Code
Before getting into the details about how translation occurs in cells, we will first consider the genetic code. Even without knowing how the genetic code works, from our knowledge of macromolecules, we can make some assumptions. In using RNA to make a protein, we are going from the language of nucleic acids (in this case, a polymer of RNA nucleotides) to the language of proteins, which are made up of amino acids. Remember from chapter 3 that mRNA sequence contain only four nucleotides: A, C, G, and U. But there are 20 different amino acids to be encoded. So, the genetic code cannot have a single nucleotide correspond to a single amino acid, as there are many more amino acids than there are nucleotides. Additionally, the genetic code needs to indicate where translation starts and where it should end, similar to how the promoter and terminator sequences act in transcription. Finally, the genetic code must be specific: to be a useful code, a particular sequence of nucleotides should consistently specify a particular sequence of amino acids.
The genetic code (Figure 5.2) was discovered in the 1960s, and we will use it extensively to predict the outcomes of gene expression. In translation, cells read three-letter groupings of nucleotides, or codons. Since there are four nucleotides and three letters per codon, that creates 64 different combinations. Each combination is represented in Figure 5.2, and either specifies an amino acid or is a stop codon, which means it will halt the process of translation.
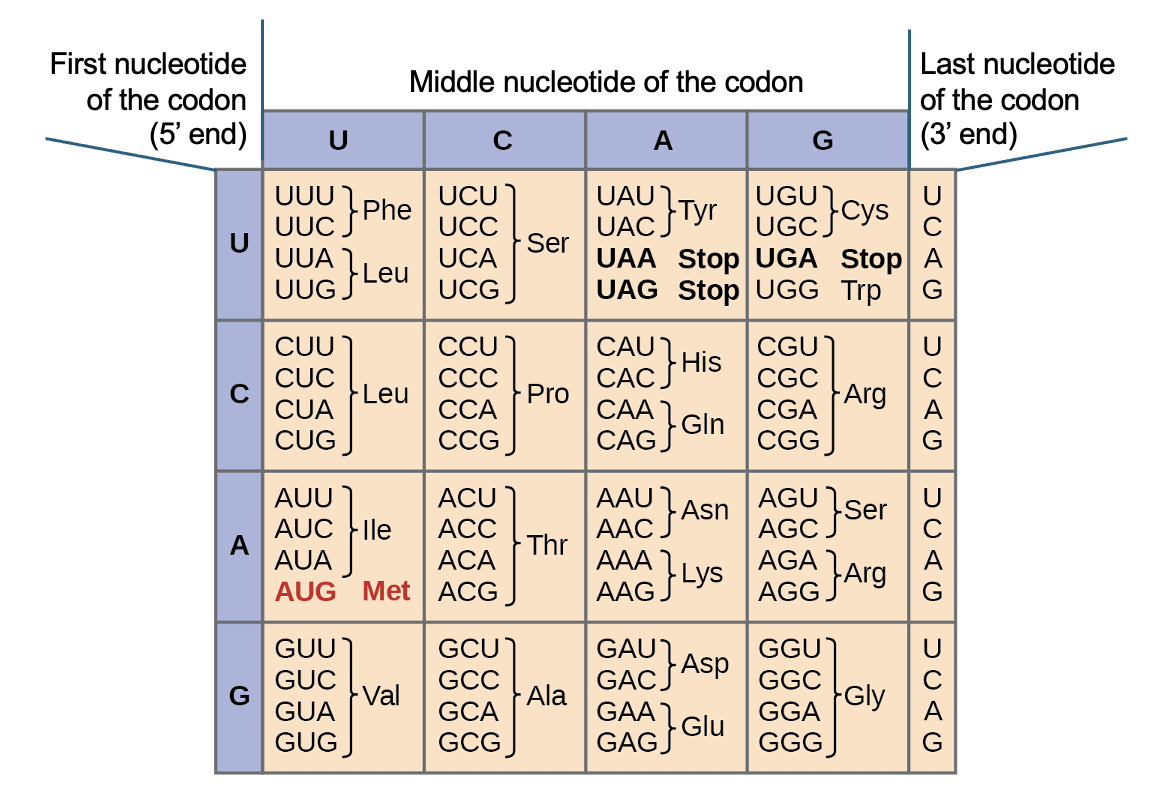
Notably, the codon 5’-AUG-3’ encodes both an amino acid, Met, and is the start codon. When translation occurs in the cell, it begins at the start codon, or 5’-AUG-3’, in the mRNA sequence. In eukaryotes, this is typically not at the beginning of the mRNA, but can be found by starting at the 5’ end of the mRNA and scanning towards the 3’ end. The first 5’-AUG-3’ encountered indicates both where translation will start, and sets the reading frame, or the specific three-letter groupings to be translated using the genetic code table. After the start codon, every codon is translated to its corresponding amino acid, until one of the three stop codons is reached. When the stop codon is read, translation ends without adding any additional molecules to the chain. As with the start codon, you should not expect to find the stop codon at the very end of the mRNA sequence. Thus, you will typically observe mRNA sequence before the start codon and after the stop codon, and you shouldn’t cut that sequence off when you write out mRNA sequences. We will discuss the importance of these untranslated regions in a later chapter.
To use the genetic code table accurately, first note that all sequences are depicted from 5’ and 3’ and so that is the way the sequence to be translated must be oriented. If by chance you have a sequence in a 3’ to 5’ direction, you’ll need to rearrange it to the correct orientation using the process described near the end of the chapter 4. Once you’ve checked that, you can then just look up each codon (the set of three nucleotides). For example, if you have the codon 5’-UUC-3’, what does that code for? From Figure 5.2, we can see this sequence codes for the amino acid Phe, which is the abbreviation for phenylalanine. Again, it’s important to check that your sequence is 5’ to 3’, because if we read as 5’-CUU-3’, it codes for Leu (Leucine), which is a different amino acid.
Exercises
Use the flashcards to practice translating a sequence, then review the steps outlined below.
The first step is to confirm the sequence is oriented correctly, from 5’ to 3’. Then, find the start codon (5’-AUG-3’), scanning the sequence from 5’ to 3’. Once identified, read every codon (every group of three nucleotides) until you reach a stop codon (5’-UAA-3’, 5’-UAG-3’, or 5’-UGA-3’). For each codon you translate, write down the three-letter abbreviation from the genetic code figure. The first amino acid translated (Met, or methionine) is at the N terminus of the protein, and each additional amino acid is added to the C terminus of the chain. You can refresh your memory of these terms by reviewing the structure of a polypeptide from Chapter 3.
The genetic code is specific, redundant, and universal
As you work with the genetic code table, you might notice some important features. As mentioned earlier, every one of the 64 codons possible is represented. This means the genetic code is specific and unambiguous. However, there are only 20, not 64, different amino acids to encode, and we can see that several different sequences code for the same amino acid (for example, there are six different ways to code for leucine, serine, and arginine!). Put more simple, the code in some cases is redundant. This is an important idea that we will come back to this idea when we discuss mutations, or changes to the genetic information. One final key feature of the genetic code is that it is universal—there is not a separate code for bacterial gene expression vs fruit fly gene expression. Instead, all living things translate a given mRNA sequence to the same amino acid sequence. A sequence from a human cell, placed into a yeast or bacterial cell, will produce the same set of amino acids when expressed as it did when in the human cell. In fact, this type of experiment has been carried out successfully in countless research labs, allowing for detailed study and manipulation of sequences.
Section 5.2 Molecules of Translation
Now that we’ve discussed the basics of translation, we will explore how this process works in cells. A cell doesn’t have a genetic code table to decode the mRNA sequence, but instead must rely on chemical interactions between components of the translation machinery. There are proteins, functional RNAs, and lots of intermolecular forces required for this process to work. Why are so many different molecules required? One reason is that translation involves transferring information from one type of macromolecule to the other (from nucleic acid to protein), so many adaptors and enzymes are required in the process. We’ll briefly touch on just a few of these molecules, but there are many more that we won’t cover in this book.
tRNA
One special functional RNA required for translation is a tRNA, which we encountered before in Chapter 3 (Figure 3.16). A tRNA is encoded by a gene and is transcribed but not translated, and there are hundreds of tRNA genes in the human genome. A simple schematic of a tRNA interacting with an mRNA is shown in Figure 5.3a, and an even simpler cartoon in Figure 5.3b.
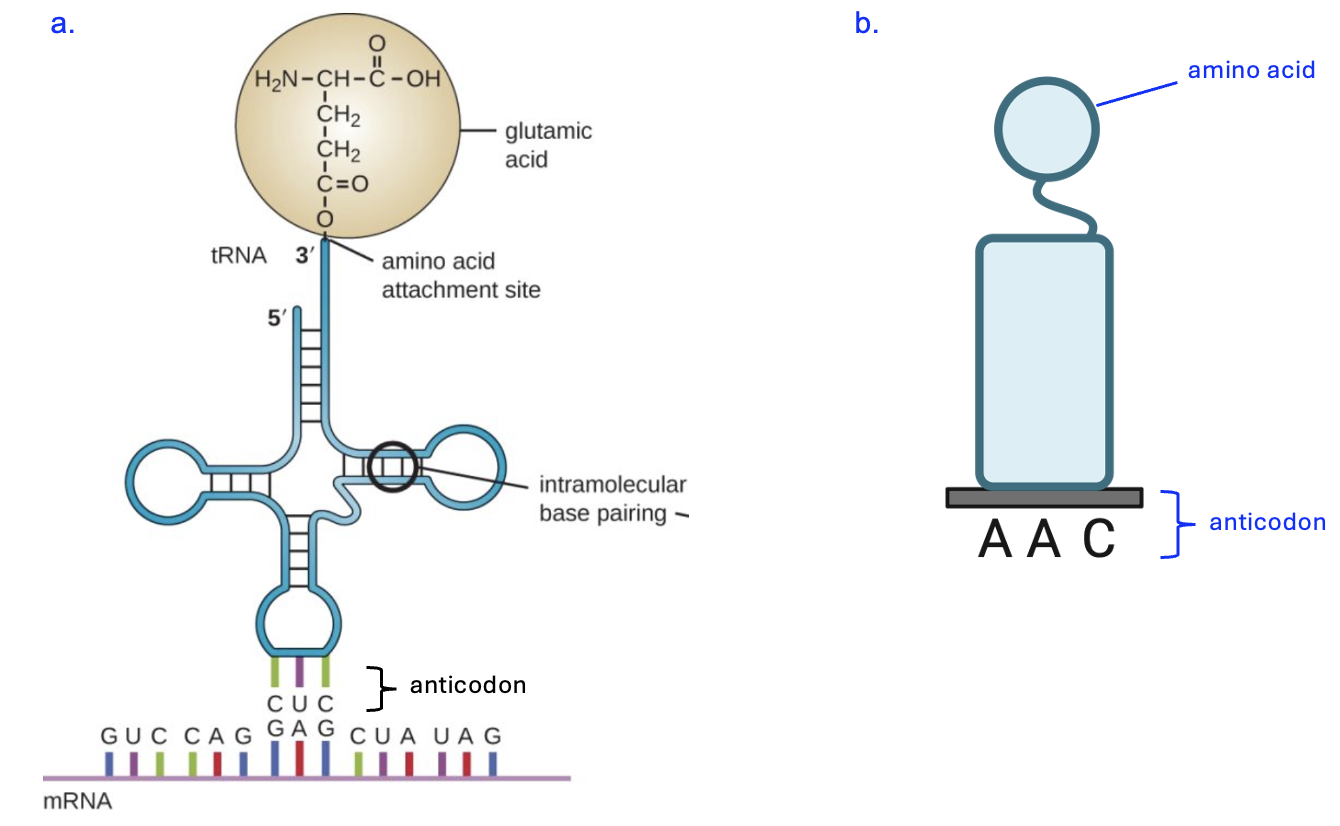
All tRNAs have the same basic clover leaf structure, formed by base pairing within the short tRNA strand. However, two important features that vary among tRNAs are the anticodon sequence, which interacts with codons in the mRNA, and the specific amino acid that is covalently attached to the tRNA strand.
What kind of interaction occurs between the tRNA and mRNA? Notice that the mRNA has the sequence 5’-GAG-3’, and the tRNA has the sequence 3’-CAC-5’, and the interaction follows the base pairing rules of the nitrogenous base C pairing with G and the nitrogenous base A pairing with U. Thus, this is base pairing between nucleic acids as we have seen before, with hydrogen bonding interactions being the basis for the pairing. Given that the tRNA can both interact with mRNA and carry an amino acid, it can serve as the adaptor or translator tool between nucleotide and amino acid languages. If you return to the codon table and look up 5’-GAG-3’, you will find this codon codes for the amino acid Glu, or glutamic acid. Based on the anticodon in Figure 5.3b, what amino acid should be attached? Hint: the genetic code table has mRNA codons, not tRNA anticodons, so first think about the mRNA sequence that this tRNA would bind to.)
The tRNA connected to an amino acid is called “charged,” not in the sense of it having a positive or negative charge, but in the sense that it is ready to be used (much like your phone with a charged battery can be used). The covalent bond between the tRNA and the amino acid is created by another protein enzyme, the aminoacyl tRNA synthetase (Figure 5.4).
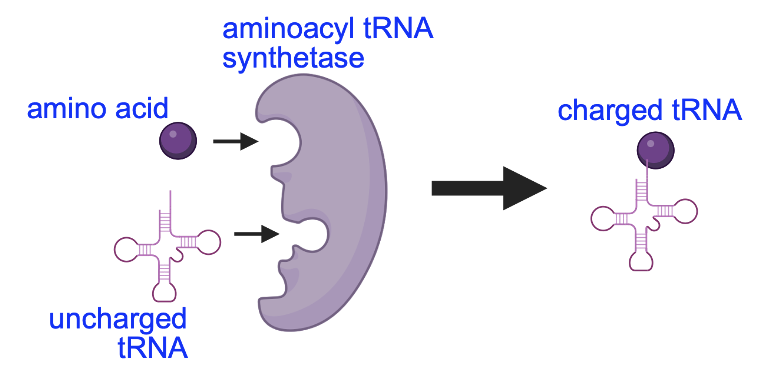
There are twenty types of these synthetases in the cell, one for each amino acid in the genetic code. Each synthetase enzyme binds to a specific amino acid and an uncharged tRNA, and creates a covalent bond between them. The molecular machine that carries out translation, the ribosome, will eventually remove the amino acid from the tRNA (making the tRNA uncharged) to form the peptide bond between amino acids. To be used again in translation, the tRNA will need to be charged with another amino acid by the tRNA synthetase enzyme.
Ribosomes
As mentioned above, the cell structure where translation and peptide bond formation take place is the ribosome, a complex molecular machine consisting of two parts, or subunits, that assemble on the mRNA sequence to be translated. Figure 5.5 shows a structural model and a simplified cartoon of the ribosome.
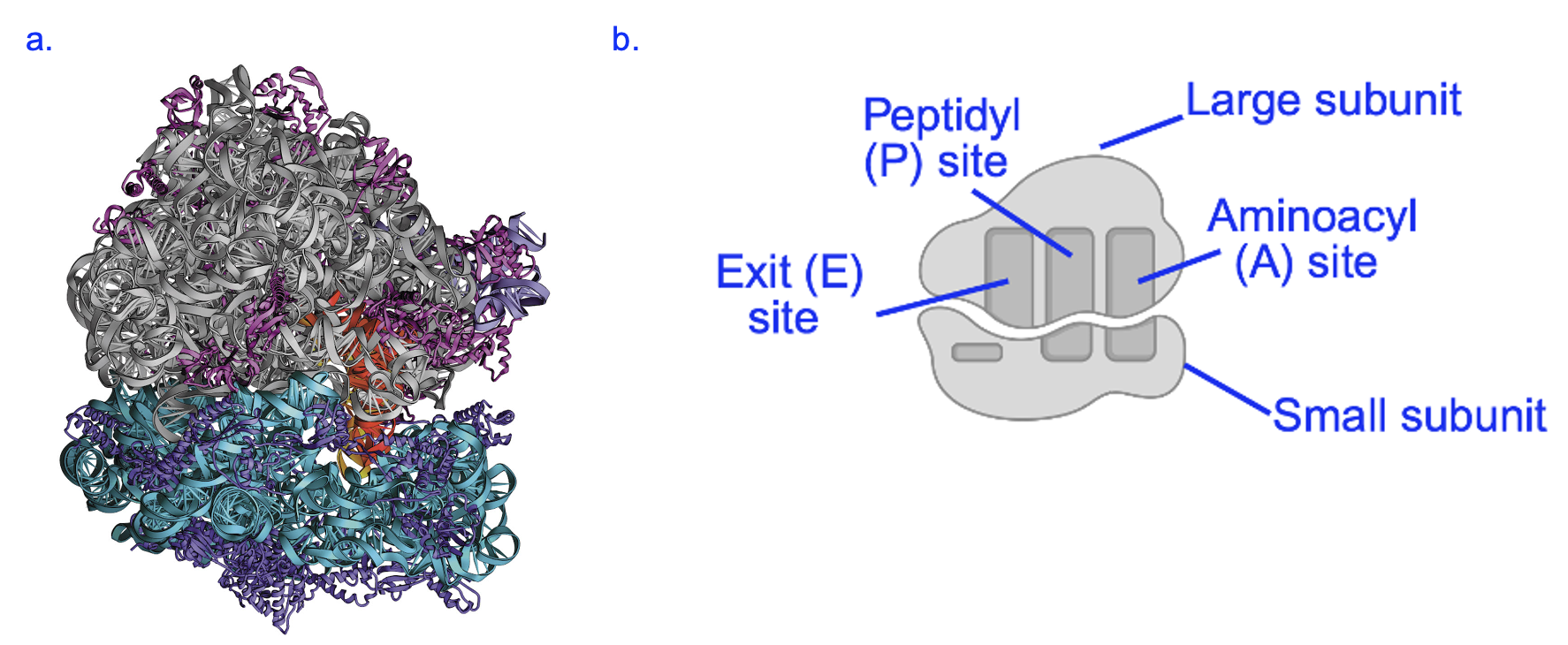
The ribosome is formed from multiple RNA (ribosomal RNA, or rRNA) and protein molecules, which are shown in part a as gray and blue structures (rRNA) or light and dark purple structures (protein) (Figure 5.5a). Remarkably, it is the rRNA components of the ribosome that carry out the chemical reactions of translation, including the formation of the peptide bond between amino acids. Within the large subunit, the ribosomal structure creates three sites, called aminoacyl (A), peptidyl (P), and exit (E) sites, where specific steps in the translation process occur (shown in Figure 5.5b). If an mRNA were present, it would be sandwiched between the large and small subunits. In addition to its catalytic activity, another function of the ribosome is to act as a scaffold to coordinate the mRNA and tRNA molecules in translation. At any given time, one mRNA and no more than three tRNAs are within the ribosome.
Section 5.3 Process of Translation
Now that we are familiar with some of the key molecules in translation, let’s focus on the process as it occurs in the cell. We already know the initial step of translation—finding the start codon. Additionally, the first amino acid of the polypeptide chain should be Met, the amino acid encoded by the start codon. In eukaryotic cells, the small ribosomal subunit is preloaded with a tRNA carrying Met (Figure 5.6a). This structure assembles at the 5’ end of the mRNA to be translated, moving towards the 3’ end and scanning the sequence for the start codon, 5’-AUG-3’. When the sequence is reached, hydrogen bonds formed with base pairing stabilize the small subunit with the Met-tRNA in the P site (Figure 5.6b). The large subunit then binds, creating the A site centered around the codon following the start codon (Figure 5.6c).
The charged tRNA that can base pair with the next codon enters the A site and is stabilized by hydrogen bond interactions (Figure 5.7a). Then, the catalytic RNA within the ribosome breaks the covalent bond between the Met amino acid and the first tRNA. This allows the catalytic RNA to create a peptide bond between Met and the amino acid attached to the tRNA in the A site (Figure 5.7b). Finally, the entire ribosome moves down the length of one codon so the tRNA with a dipeptide attached is now in the P site and the next codon sequence is now within the A site. The uncharged tRNA that previously carried Met is in the exit site, and is ejected from the ribosome. This creates a space for the corresponding tRNA to enter the A site (Figure 5.7c).
Exercise
Translation continues in this fashion until a stop codon is reached. Cells do not make tRNAs that base pair with the stop codons; instead, a release factor protein enters the A site and ends translation (Figure 5.8a). This causes the ribosome to detach the polypeptide from the tRNA in the P site and for the large and small ribosome subunits to detach from the mRNA (Figure 5.8b).
The ribosome subunits will assemble on a different mRNA to translate it, and the mRNA just translated may be translated again many more times. The polypeptide that was produced will begin folding to adopt a specific three-dimensional shape that is connected to its function. Please see Chapter 6 for more details!
Section 5.4 Cellular Location of Translation
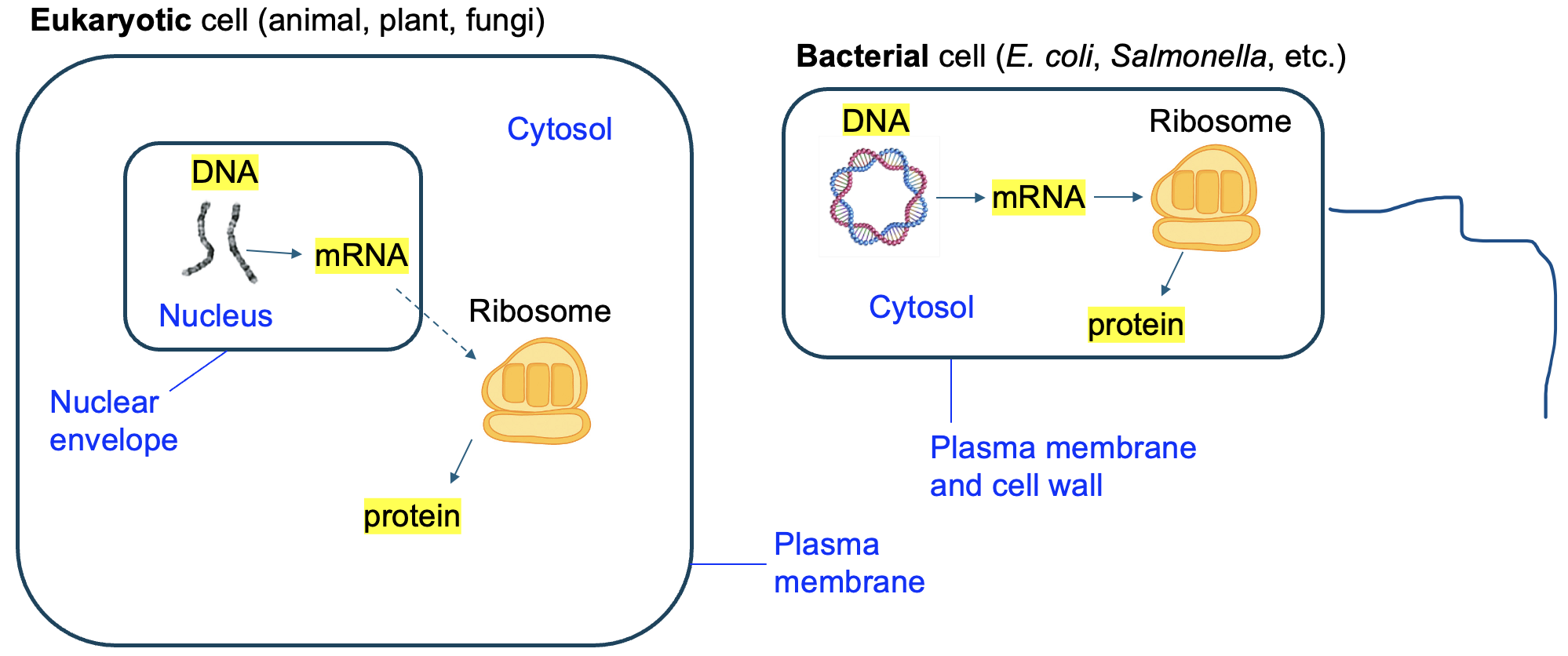
Lastly, let’s return to the models of bacterial and eukaryotic cells that we studied in the previous chapter (shown again in Figure 5.9). Notice again that the bacterial cell has no internal compartments. Everything happens in the cytosol, including transcription. But a eukaryotic cell has a special feature called the nucleus, which contains the genomic DNA. As a result, transcription happens in the nucleus in eukaryotic cells. However, the ribosome that we know carries out translation, is in the cytosol. So that means that mRNA must leave the nucleus and enter the cytosol to be translated. But secondly, and more relevant for this chapter, this means that translation occurs in the cytosol of both eukaryotic cells and bacterial cells.
three-letter groupings of nucleotides represented in the genetic code table, based on the reading frame
sequence in an mRNA sequence being translated that indicates where translation will halt
the sequence 5'-AUG-3' in an mRNA that indicates where translation starts
the specific three-letter groupings to be translated using the genetic code table, determined by the first 5'-AUG-3' encountered in translation.
in the context of the genetic code, all possible 3-nucleotide combinations found in mRNA have an unambiguous meaning, corresponding to a specific amino acid or a stop codon
in the context of the genetic code, more than one codon can specify the same amino acid
in the context of the genetic code, all organisms use the same code for translating RNA sequences to amino acid sequences
